写在前面
前两章我们做了 检测 和 诊断。这一章是补丁:拿到诊断报告知道哪里需要补内容了,但又写不出来怎么办?
Geolix 的内容产出模块就是干这个的 —— 从选题 → 大纲 → 成稿 → SEO 自检全链路 AI 辅助,30 分钟产出一篇 GEO 友好的素材。重点是 让 AI 用你自己的事实写,而不是套话。
内容工作流的 4 步
左侧导航 → 内容产出 → 文章生成:
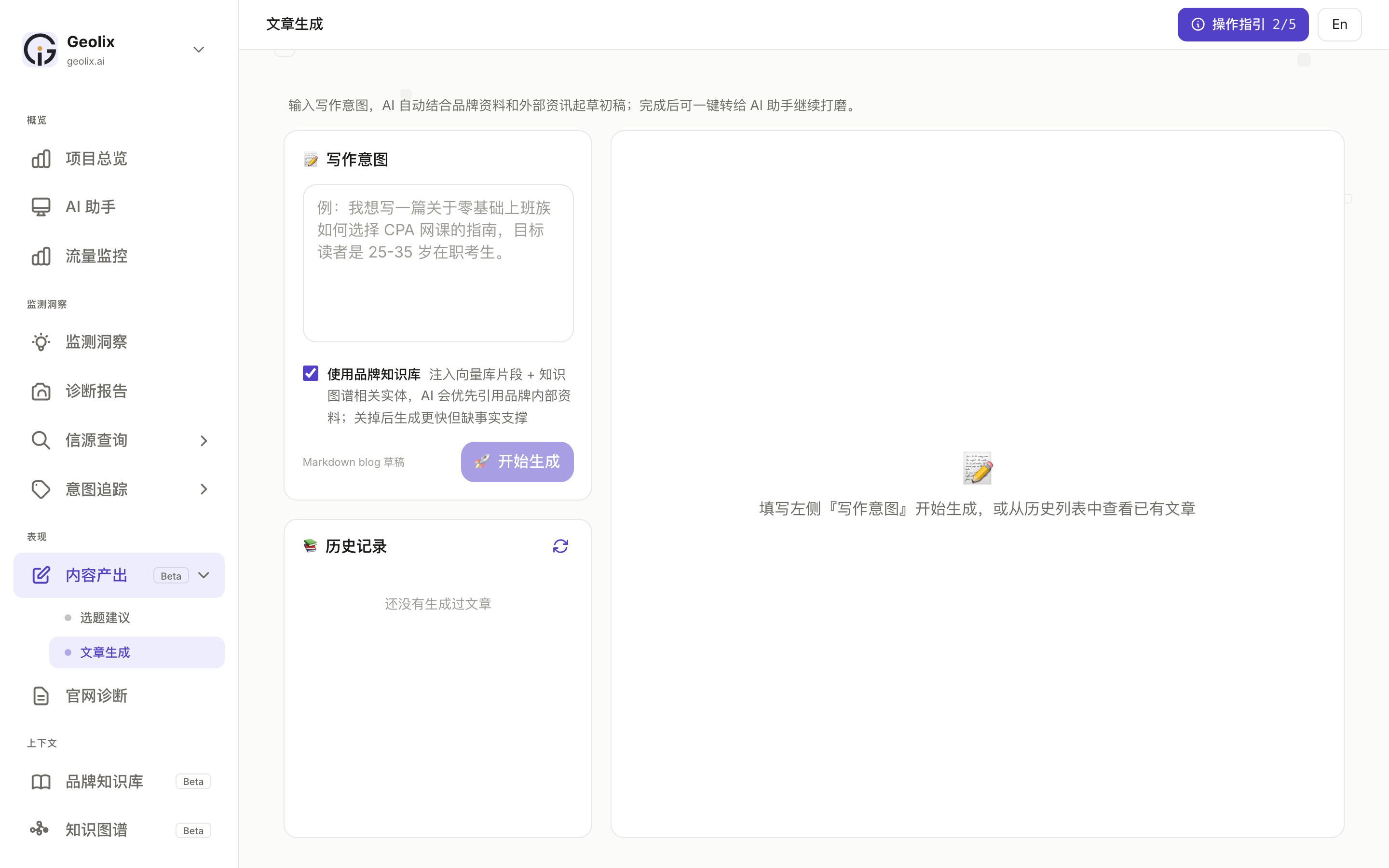
界面三栏:
- 左侧 「写作意图」:输入框(例:我想写一篇关于零基础上班族如何选择 CPA 网课的指南,目标读者是 25-35 岁在职考生)
- 中间 「历史记录」:还没生成过文章
- 右侧 实时预览:填写左侧"写作意图"开始生成
底下勾选「使用品牌知识库」会注入向量库片段 + 知识图谱相关实体,AI 会优先引用品牌内部资料;关掉后会更快但缺事实支撑。
完整工作流分 4 步:
- 选题建议(
topic_ideas):根据品牌信息 + 知识库 + 历史选题,给 5-8 个候选 - 规划阶段(
article_workflow_plan):选定一个选题后,AI 出大纲 + 关键引用源 - 成稿阶段(
article_workflow_draft):用大纲 + 知识库 RAG 出 Markdown 初稿 - SEO 自检(手动 checklist + 自动 lint):发布前确保 GEO 友好
第一步:选题建议
很多人写不出来不是文字不行,是不知道写什么有用。
topic_ideas 会基于你项目的 4 类信号生成候选:
- 品牌定位:你填的 description + selling_points + target_audience
- AI 引擎检测历史:哪些意图问题命中率低 → 反推内容缺口
- 竞品分析:竞品发了什么主题、你没覆盖
- 热点行业关键词
每条建议带:标题、读者画像、预期长度、关键引用源、预估 GEO 价值(low/med/high)。
挑一条进入规划阶段。
第二步:规划阶段
article_workflow_plan 干 3 件事:
- 大纲:4-8 个 H2,每个 H2 下 1-3 个 H3,标注每段论点和目标字数
- 引用骨架:每个 H2 标注需要从知识库 / 联网搜索拿什么事实支撑
- SEO 元数据预填:title / description / slug / tags 候选
可以在大纲上直接编辑:删 H2、加 H3、修引用方向。
💡 大纲不准时怎么办 —— 直接在前端"重新规划"按钮重新跑。大纲质量直接决定成稿质量,这一步多花 5 分钟值得。
第三步:成稿阶段 —— RAG 拼上下文
article_workflow_draft 是核心:
- 把大纲拆成段
- 每段去项目知识库(Milvus 向量检索 + BM25 混合)拉 5-10 条相关 chunk
- 把这些 chunk + 段大纲 + 全局品牌信息一起喂给 LLM
- LLM 输出该段的 Markdown
- 拼接成完整文章
关键:知识库里有什么决定成稿质量。 知识库空了 AI 只能用通用知识写,出来还是套话。
怎么喂知识库
左侧导航 → 品牌知识库:
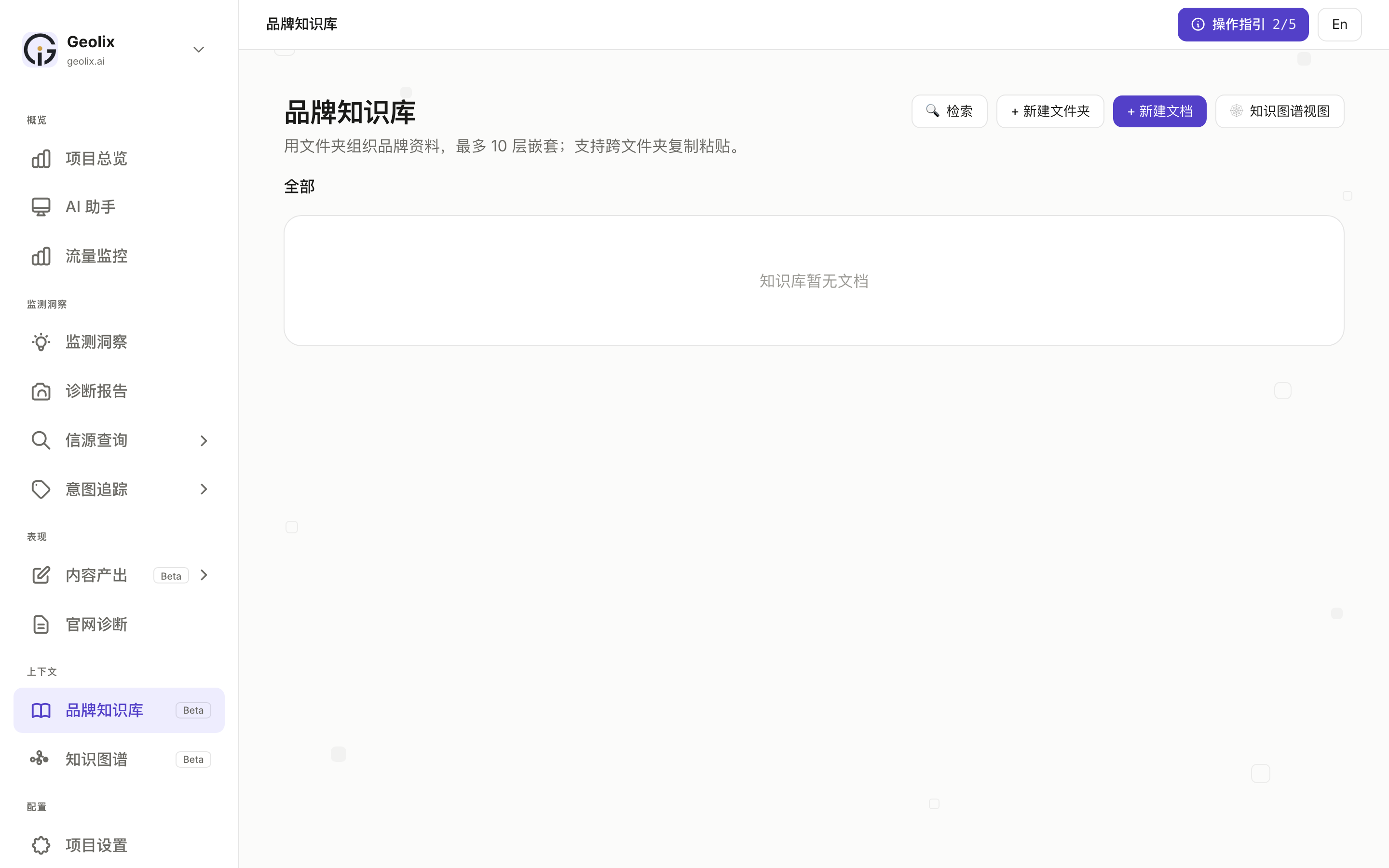
支持 3 种入口:
- 新建文档:贴 Markdown / 富文本,直接存
- 新建文件夹:最多 10 层嵌套,跨文件夹复制粘贴
- 检索:在录入的全部文档里关键词 / 语义混合搜索
- 右上角「知识图谱视图」会把已有内容自动抽实体 + 关系,方便看你内容覆盖了哪些"概念领域"
建议优先入库:
- 官网产品介绍页(让 AI 知道你卖什么)
- 白皮书 / 技术博客 / 案例报告(事实和数字的来源)
- 爆款文章(让 AI 学你的语气)
- 目标客户访谈摘录(让 AI 知道用户语言)
入库后会自动 chunk + embedding(Qwen text-embedding-v4,768 维)+ 建索引。第二次成稿就会用到。
第四步:发布前 GEO 自检 checklist
成稿后跑这 7 项:
- ✅
<title>35-60 字符,含品牌名 + 主关键词 - ✅
<meta description>80-160 字符,跟正文 H1 不重复 - ✅ JSON-LD Article schema(含 author / datePublished / image / publisher)
- ✅ JSON-LD BreadcrumbList(首页 > 博客 > 当前)
- ✅ Canonical URL 写绝对路径
- ✅ 正文事实密度:随便挑 3 段,每段至少有 1 个具体数字 / 案例 / 对比
- ✅ 图片
alt全填,文件名带语义(不是IMG_001.png)
长期跟踪
发了 5-10 篇后,回到「监测洞察 → 可见性」重新跑一次 25 个意图问题。对比第一次 baseline:
- 总体可见度涨没涨?
- 哪几个意图问题命中率从 0 → 60%+?
- 引用源里有没有你新发的博客?
涨幅最大的那批,看共性 —— 是话题、长度、引用源数量、还是结构 —— 然后复制写法继续。
不涨的话,回到第二章重新跑诊断,可能是网站结构层面还有问题。
下一章预告
第四章:知识图谱深度运营 —— 项目 KG 建模 + 内容布局
我们会拆 Geolix 的「知识图谱」功能:怎么从已有内容自动抽实体 + 关系(人/产品/技术/场景/客户),看你的内容覆盖了哪些"概念领域",又遗漏了哪些。这是用结构化方式做长期内容布局,比单篇博客的视角高一层。
完整的 7 项 SEO 自检 checklist + 项目知识库示例模板,发邮件到 public@geolix.ai 主题写 "blog ch3 templates" 即可领取。