写在前面
第一章 我们做了第一次品牌可见度检测,看到 5 个 AI 引擎对你品牌的实际提及率。
但拿到分数只是开始——如果分数低,怎么知道是官网内容差还是没人提到你?修哪儿才能涨? 这一章我们讲 官网诊断:用 Geolix 给你的官网做一次"AI 友好度"体检,找出短板,逐条修复。
AI 怎么"看"你的网站
跟 Google 爬虫不同,ChatGPT / Claude 这些 LLM 不会自己爬 Web;它们看的是预训练时索引过的语料,或者用户调用时通过 search tool(Bing / Brave / 自家爬虫)拉回来的实时网页。
不管哪种方式,AI 提取你品牌信息的成败取决于 4 个维度:
- 元信息可读性 ——
<title>、<meta description>、Open Graph、canonical 是否齐全准确 - 结构化数据 —— JSON-LD 的
Organization/Product/Article/BreadcrumbList等 schema 是否就位 - 正文事实密度 —— 内容里有没有具体数字、案例、对比,而不是"我们是行业领先"这种话术
- 权威信号 —— 作者、发布日期、引用来源、第三方背书
Geolix 的官网诊断会针对这 4 项各打 0-100 分,再加权出总分。
跑一次诊断(30-60 秒)
左侧导航点「官网诊断」,进入诊断台:
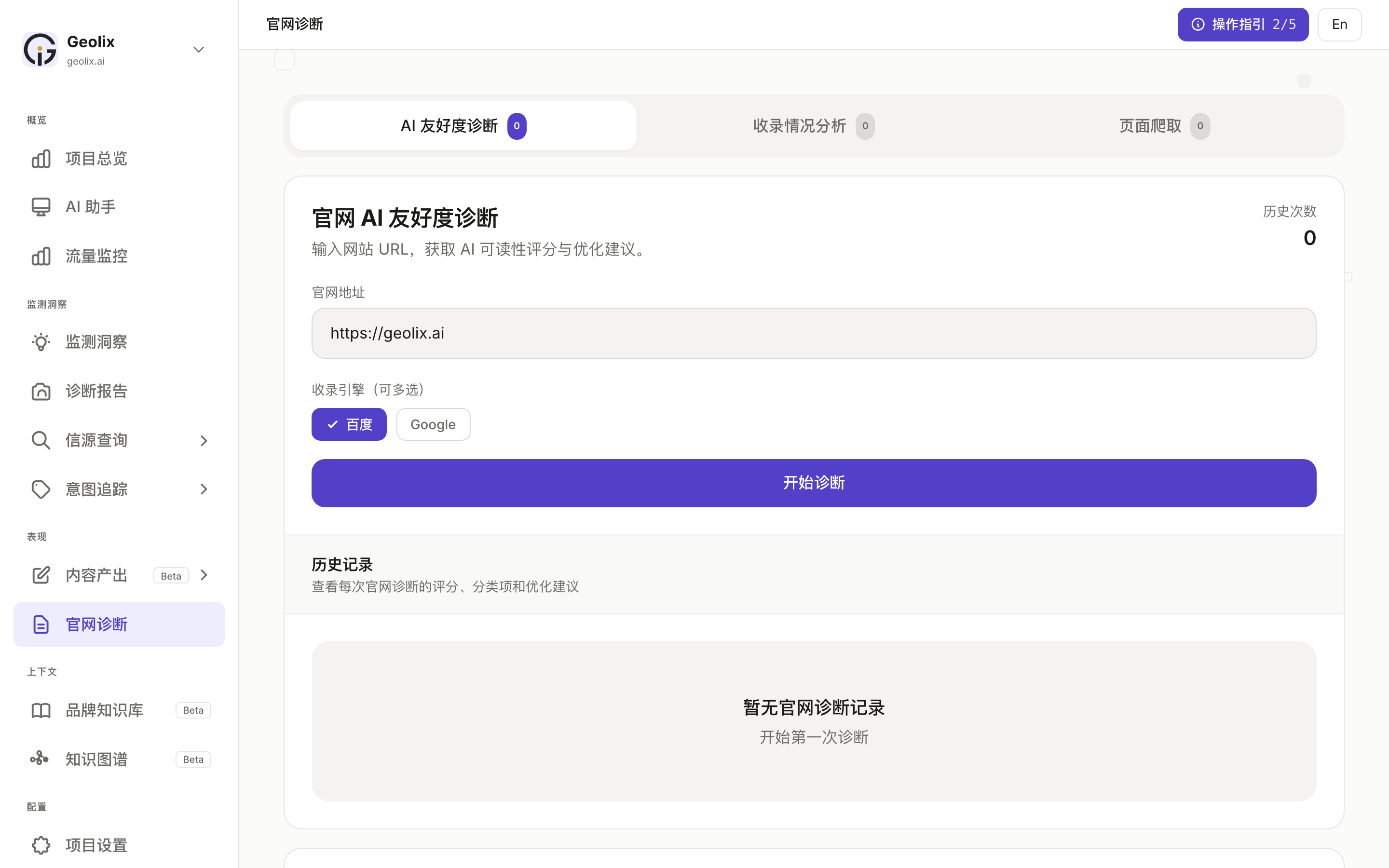
界面分 3 个 tab:
- AI 友好度诊断:给页面 4 维度打分 + 给优化建议
- 收录情况分析:检测百度 / Google 等传统搜索引擎对你域名的收录数据
- 页面爬取:单页爬取调试(看反爬挡没挡你、内容能不能正常提取)
最常用的是第一个 AI 友好度诊断。流程:
- 输入 URL(默认填你项目的官网域名)
- 选收录引擎(百度 / Google,可多选)
- 点「开始诊断」
后端会:
- 用
curl_cffi+ 真实 Chrome TLS 指纹拉页面(不然会被反爬挡掉) - 把
<head>的全部元素逐项检查 - 解析所有 JSON-LD / Microdata / RDFa
- 用 LLM 评估正文事实密度和权威信号
- 给 4 维度子分 + 总分 + 具体扣分原因
30-60 秒后报告出来,所有诊断记录会落在底部「历史记录」里,按时间倒序,方便对比改动前后的分数变化。
4 类最常见的 GEO 问题 + 修复
下面这些坑我们在几十个网站上反复见过,按出现频率排:
🔴 问题 1:<head> 元信息散乱 / 缺失
典型症状:诊断分 50-65,子分卡在「元信息可读性」40 以下。
怎么发现:F12 看 <head>,对照下面 checklist 数缺哪几项。
<title>:35-60 字符,含品牌名 + 主关键词<meta name="description">:80-160 字符,独立写而非复制 H1<link rel="canonical">:当前页绝对 URL<meta property="og:title">/og:description/og:image/og:type<meta name="twitter:card" content="summary_large_image">- 多语言站点:
<link rel="alternate" hreflang="...">一组
怎么修:如果是 Nuxt / Next 站点,每页用 useSeoMeta() / <Head> 显式写。如果用 WordPress / Webflow,装 Yoast / RankMath 之类的插件批量补。
🔴 问题 2:完全没有结构化数据(JSON-LD)
典型症状:诊断分 35-50,子分「结构化数据」直接 0。
怎么修:至少在首页加 Organization schema:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Your Brand",
"url": "https://yourbrand.com",
"logo": "https://yourbrand.com/logo.png",
"description": "一句话说清楚你是干什么的,含 1-2 个关键词",
"sameAs": [
"https://twitter.com/yourbrand",
"https://linkedin.com/company/yourbrand"
]
}
</script>
产品页加 Product,文章页加 Article,列表页加 BreadcrumbList。
🔴 问题 3:正文事实密度低("营销腔")
典型症状:诊断分 60-70,子分「正文事实密度」< 50。LLM 评估返回类似"内容偏宣传性,缺少可引用的具体数据"。
典型反例:
"我们是行业领先的 SaaS 平台,致力于赋能企业数字化转型,提供一站式解决方案。"
AI 看完这段 → 不知道你是干啥的、不知道用户是谁、不知道你比对手强在哪 → 不会主动提及。
怎么修:用 3F 原则 重写每段:
- Fact(事实):具体功能、定价、客户名、数字
- Figure(数据):响应时长、准确率、节省成本百分比
- Foothold(立脚点):对比对象、行业基准
改写示例:
"Geolix 在 ChatGPT / Claude / Gemini / 豆包 / DeepSeek / 通义千问 6 个 AI 引擎里检测品牌提及率,平均 4 分钟跑完 25 个意图问题。一家跨境支付 SaaS 把可见度从 12% 提到 47% 用了 3 周。免费版每月 50 次检测。"
🟡 问题 4:缺权威信号
典型症状:博客 / 案例 / 教程类页面尤其常见,诊断分 65-75。
怎么修:
- 文章页:作者署名 + 头像 + 1 句作者背景 + 发布日期 + 更新日期
- 案例页:客户 logo + 客户名(如能公开)+ 数据出处("客户内部 BI 数据,2025 Q3")
- 引用第三方:引用 Gartner / IDC / 内部数据时附
<cite>或加source: ...注释
一个真实案例
一家做 跨境支付 SaaS 的客户,2025 年 12 月接入 Geolix 时首次诊断 41 分(满分 100):
- 元信息 28(首页只有
<title>) - 结构化数据 0(没 JSON-LD)
- 事实密度 52(首页 8 段全是"赋能 / 一站式 / 引领")
- 权威信号 45(团队页没作者,案例页缺数据)
按上面 4 步修了 2 周,第二次诊断 83 分。同期 ChatGPT 主动提及率从 12% 涨到 47%,Claude 从 18% → 53%。
不是"修完 AI 立刻看见",而是修完后下次 LLM 重新爬 / 用户问到时引擎更愿意把你当成可信源。
你的 next step
- 现在去项目「官网诊断」跑一次 baseline
- 拿到 4 维度子分后对照本文 4 类问题逐条改
- 改完隔一周再跑一次,看子分变化
- 子分 ≥ 80 了再发起新一轮品牌检测,对比第一次的提及率
下一章预告
第三章:不会写就让 AI 写 —— GEO 友好内容生成与发布
我们会拆 Geolix 内容工作流:从选题建议 → 大纲规划 → 成稿 → SEO 自检。重点讲 品牌知识库 怎么喂事实给 AI,让 AI 写出不是套话而是有数据有事实的 GEO 素材。
4 类问题的修复 checklist 完整版本会发到邮件订阅。订阅请发空邮件到 public@geolix.ai,主题写 "subscribe blog"。